
티스토리 뷰
공연 동행 구인 웹 서비스에서 동행 구인 게시글 목록 조회 API를 구현하며
많은 양의 동행 구인글 반환이 필요하여
서버 부하 방지를 위해 커서 기반 페이지네이션을 적용해보았습니다😀
오프셋 방식과 커서 방식 비교
페이지네이션은 모든 데이터를 전달하는 것이 아닌, 특정 개수의 필요한 데이터만 전달하는 방법을 의미합니다.
페이지네이션하면 대표적으로 두 가지 방법이 있습니다.
1. 오프셋 기반 페이지네이션
오프셋을 사용하게 되면, 오프셋 앞 데이터를 읽고 그 이후의 n개의 데이터를 읽어서 반환하게 되므로, 성능 저하 문제가 발생합니다.
2. 커서 기반 페이지네이션
커서 아이디를 기준으로 다음 n개의 데이터를 반환해주는 방식입니다.
간단히 말하면
오프셋 기반 방식의 경우
90번째(오프셋) 데이터 이후의 5개의 데이터를 줘.
➡️ 90+5개의 데이터를 읽게 되고
커서 기반 방식의 경우
90번째(커서아이디) 데이터 이후의 5개의 데이터를 줘.
➡️ 5개의 데이터만 읽게 됩니다.
👉오프셋 값이 커질 수록 성능 저하가 심해짐을 알 수 있습니다. 또한 LIMIT을 이용하여 데이터를 가져오기 때문에 각각의 페이지를 요청하는 사이에 데이터의 변화가 있는 경우 데이터가 중복으로 조회될 수 있다는 문제점이 있습니다.
특정 id 이후의 데이터를 중복없이 효율적으로 가져오기 위해 커서 페이징을 사용해보았습니다.
커서 기반 페이지네이션 적용하기
커서 기반 페이지네이션을 통해 데이터를 조회하는 흐름을 간단히 살펴보면
1. 클라이언트
클라이언트가 받은 마지막 데이터의 id(➡️cursorId)와 원하는 데이터 갯수를 서버로 전달합니다.
2. 서버
cursorId 이후의 데이터를 클라이언트가 요청한 갯수만큼 가져와 반환합니다.
AccompanyController
클라이언트로부터 요청을 받은 Controller 코드를 먼저 살펴보겠습니다.
@GetMapping("/posts")
public ResponseEntity<AccompanyPostsResponse> getAccompanyPosts(
@RequestParam(required = false) Long cursorId,
@RequestParam(required = false, defaultValue = "10") int size) {
return ResponseEntity.ok(accompanyService.getAccompanyPosts(cursorId, size));
}
쿼리파라미터 값을 통해, cursorId와 size 값을 받도록 하였습니다.
여기서, 최초 조회 시에는 클라이언트가 받은 마지막 데이터의 id가 존재하지 않기 때문에 이에 대한 처리가 필요합니다.
cursorId를 required = false로 설정하여
cursorId 값을 제공하지 않는 경우 ➡️ 즉 cursorId가 null 값인 경우
가장 최근의 데이터 size 갯수만큼을 반환해주도록 처리해주었습니다.
👇아래 코드 참고
AccompanyServiceImpl
public AccompanyPostsResponse getAccompanyPosts(Long cursorId, int size) {
Slice<AccompanyPost> accompanyPosts;
if (cursorId == null) {
accompanyPosts = accompanyPostRepository.findAllByOrderByIdDesc(
PageRequest.of(0, size));
} else {
accompanyPosts = accompanyPostRepository.findByIdLessThanOrderByIdDesc(
cursorId, PageRequest.of(0, size));
}
return new AccompanyPostsResponse(
accompanyPosts.hasNext(),
accompanyPosts.getContent().stream()
.map(accompanyPost ->
AccompanyPostsResponse.AccompanyPostInfo.builder()
.id(accompanyPost.getId())
.title(accompanyPost.getTitle())
.gender(accompanyPost.getGender())
.concertName(accompanyPost.getConcertName())
.status(accompanyPost.getStatus().getName())
.totalPeople(accompanyPost.getTotalPeople())
.updatedAt(accompanyPost.getUpdatedAt())
.writer(accompanyPost.getMember().getName())
.viewCount(accompanyPost.getViewCount())
.commentCount(0L) // 임시
.build()
).toList());
}
JPA를 사용하여 Paging 구현하기
서비스 코드
PageRequest로 페이징 정보를 담습니다.
- PageRequest는 Pageable의 구현체로, pageable을 레포지토리 메서드의 인자로 주게 되면, JPA가 알아서 페이징 처리를 해줍니다.
- PageRequest.of(int page, int size) : 페이지 번호와 개수를 인자로 주며, 정렬이 지정되지 않습니다.
if (cursorId == null) {
accompanyPosts = accompanyPostRepository.findAllByOrderByIdDesc(
PageRequest.of(0, size));
} else {
accompanyPosts = accompanyPostRepository.findByIdLessThanOrderByIdDesc(
cursorId, PageRequest.of(0, size));
}
레포지토리 코드
Pageable이 레포지토리 메서드의 인수로 전달되고 이를 바탕으로 로직을 처리하게 됩니다.
public interface AccompanyPostRepository extends JpaRepository<AccompanyPost, Long> {
Slice<AccompanyPost> findAllByOrderByIdDesc(Pageable pageable);
Slice<AccompanyPost> findByIdLessThanOrderByIdDesc(Long id, Pageable pageable);
}
👀 Page와 Slice의 차이점!
Page는 Slice를 상속합니다.
➡️Slice가 가진 모든 메서드를 Page도 사용할 수 있습니다.
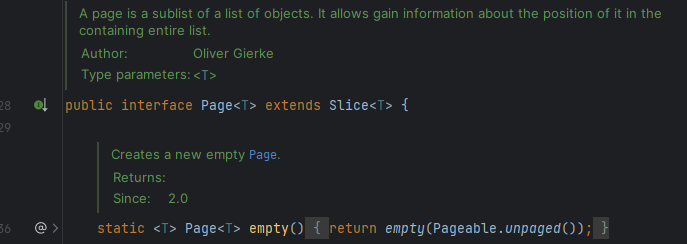
Page는 추가적으로 2가지 메서드를 구현합니다.
1. 전체 데이터 개수 반환
2. 전체 페이지 수 반환
➡️ Page는 전체 데이터 및 전체 페이지 수를 계산하기 위해서 Count 쿼리를 추가로 실행됩니다.
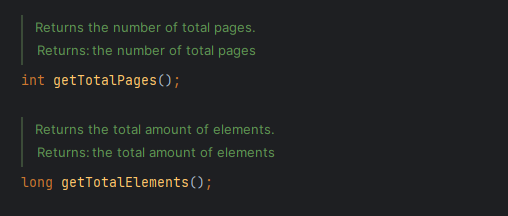
Slice는 다음 Slice 존재 여부만 판단하기 때문에 Page 리턴 타입보다 성능적으로 좋다는 것을 알 수 있습니다.
이번에 구현한 무한 스크롤 방식의 경우, 전체 페이지와 데이터 개수가 필요 없어 Slice 방식을 사용하였습니다👾
커서 방식에서 Slice나 Pageable를 사용이 꼭 필요할까?
서비스 단에서 PageRequest.of(page, size)로 Pageable을 생성하여 인수로 넘겨주게 되는데, 인수로 Pageable 대신 size만 넘겨주고 limit은 native 쿼리를 사용하여 작성하는 방법도 있습니다. 반환 값의 경우, 커서 방식 구현 시에 결국 클라이언트에 반환하는 값은 List 이기도 해서 반환 값은 Slice 대신 List에 담아서 넘겨줄수도 있습니다. 필요한 값들만 전달해서 Slice나 Pageable 없이 구현할 수 있다는 점에서 무작정 새로운 의존성을 추가한 것 같다는 생각도 들었습니다😅
'백엔드 > SpringBoot' 카테고리의 다른 글
| 조회수 동시성 제어를 위한 고민과 Update Lock 적용 (1) | 2024.04.02 |
|---|---|
| 검색 필터링을 위한 QueryDsl 동적 쿼리 적용기 (0) | 2024.03.10 |
| Spring에서 AOP를 구현하는 방법(JDK/CGLib Proxy) (2) | 2024.01.21 |
| Fetch Join과 비동기로 283배 시간 단축하기! (0) | 2024.01.21 |
| LazyInitializationException 왜 발생하고, 어떻게 해결할까🧐 (0) | 2024.01.06 |